自我监督学习有可能彻底改变计算机视觉。它的目标是从未标记的视觉数据中学习好的表示,减少甚至消除收集昂贵的手工标签的需要(Alejandro et al.)。
同域or跨域迁移学习?
我们总是希望在同一个域内进行迁移学习,以此规避跨域学习中domain gap的风险。
目前为止,之前的医学自监督任务多是在同一个数据集内评估性能,对于性能提升来说,同域迁移显然是更好的选择。
但是,现有的医学数据集相比于ImageNet来说,规模太小以至于很难学习到可靠的图像表示(representation)。
因此,我认为可以考虑怎样联合相似域的可用数据集,以训练模态指向(modality-oriented)的模型或者器官指向(organ-oriented)的模型。
目前,医学图像中的跨模态迁移还是一片处女地(Holy Grail),尽管无标注的数据容易获得而且数目总多,但是想要做成公开数据集仍旧受到诸多限制。
对于学术界而言,也许研究如何利用好跨域图像,是一个不错的选择[1]。
How Useful is Self-Supervised Pretraining for Visual Tasks?
这篇文章发表在今年的CVPR2020上面,由普林斯顿大学Alejandro等人合著,是属于Rethinking类的文章。题目的中文译名为:探索自监督预训练在视觉任务中的效果。
通读全文,作者的主要目的是调查哪些因素可以提升自监督预训练方法的效用。为了做到这一点,作者测试了各种自监督算法在合成数据集和下游任务(downstream tasks)中的表现。合成数据的好处,在于能够提供无限的注释图像,以及完全控制数据集的难度,方便对算法进行评估。
论文的研究动机:
我们观察到,许多现有的自监督评估常在few-shot设置或限制下游模型使用时进行,比如冻结预训练网络模型,只为下游任务训练一个线性层,但这并不能帮助我们获得更高的精度(性能对自动驾驶行人检测或者医学图像处理来说至关重要)。在不受标签数目限制的情况下,自我监督有多有用呢?这就是本文试图想要回答的问题。
论文的主要发现:
给定一个下游任务,随着标记数据的增多,模型的性能将会提高,并最终趋于稳定。但在实践中,标签预算是有限的,这个预算将决定train from scratch模型的准确性。在将微调(fine-tune)的自监督模型与从零开始训练(train from scratch)的基线进行比较时,可能会出现三种不同的结果(如图1所示):a)自监督比基线更准确;b)自监督达到同样的准确度,使用的标注样本减少;c)自监督在相同的标注样本数量下达到相同的准确度。在实验中,c)情况是最常出现的。
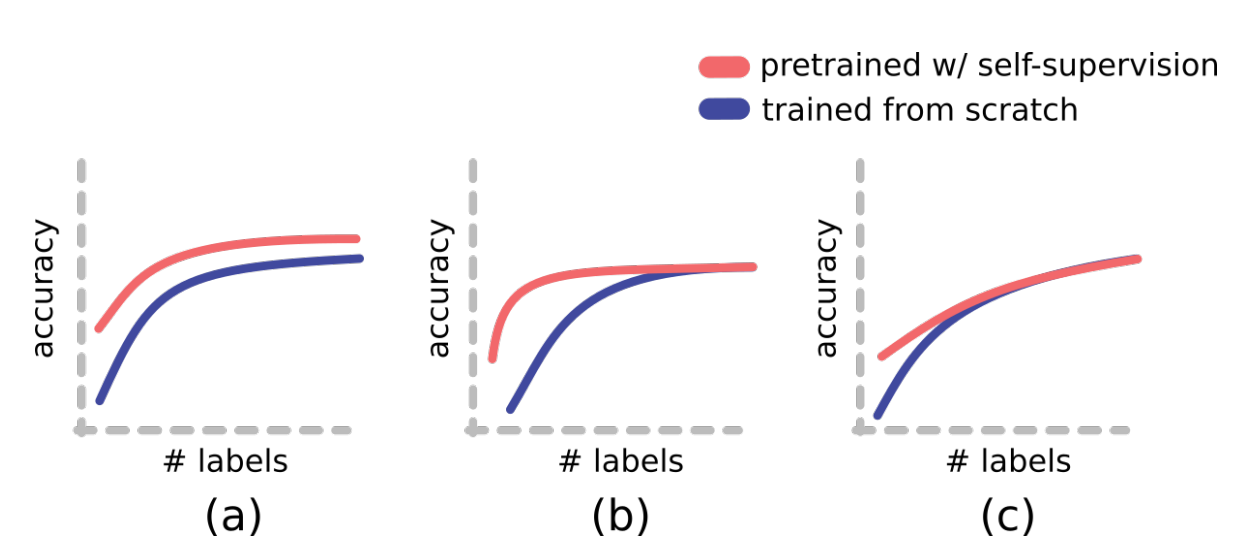
图1 自监督预训练方法在小标签预算中有用,但随着标签的增多,效用往往开始下降。
这说明,预培训的最大好处目前是在低数据体系下,在额外标签的任务性能达到稳定之前,效用(Utility)就接近于零。作者还发现,自监督在应用于更大的模型和更困难的数据时更有帮助。此外,不同pretext方法的性能在不同的downstream任务中不一致,并且线性评估性能与效用无关。
在有许多标记的例子的情况下,自监督仍然会有帮助,因为SGD训练不能保证达到全局最优,而自监督的预训练可以产生更好的表示,以帮助优化,更快更好的达到收敛(情况a)。
论文的主要贡献:
定义了数据利用效用公式: 其中,m是指从头开始训练达到性能A所需要的标签数目,n是指预训练微调达到性能A所需要的标签数目。
另外,作者构建了一个合成图像的基准(benchmark)。合成图像数据库提供了独特的优势:它可以轻易生成大量带标签的示例,还可以轻松探索各种下游任务,从分类到密集预测,从语义到几何任务。最后,它允许通过颜色、纹理和视点等因素精确控制数据的复杂性和下游任务的难度。本文的主要贡献是对所有这些方面进行了彻底的探索,从而为人们在何时何地可以期望自监督在实践中发挥作用提供了见解。
启发和思考:
对于自监督研究,一个很重要的问题就是,如何高效利用预训练中学习到的良好特征表示,保证细调模型在效用(Utility)降为零之前,就能达到稳定的downstream任务性能(避免出现c)情况)。否则,在达到一定精度之后,自监督并不能减少标注数据的依赖。
此外,自监督算法在一种情况下的性能不一定反映它在其他情况下的性能,这就强调了在不同情况下研究和评估预训练方法的重要性(Universal的方法是行不通的)。