多任务学习(Multi-Task Learning, MTL)是一种归纳迁移机制,主要目标是利用隐含在多个相关任务的训练信号中的特定领域信息来提高泛化能力,多任务学习通过使用共享表示并行训练多个任务来完成这一目标。一言以蔽之,多任务学习在学习一个问题的同时,可以通过使用共享表示来获得其他相关问题的知识。归纳迁移是一种专注于将解决一个问题的知识应用到相关的问题的方法,从而提高学习的效率。比如,学习行走时掌握的能力可以帮助学会跑,学习识别椅子的知识可以用到识别桌子的学习,我们可以在相关的学习任务之间迁移通用的知识。
背景
在1997年之前,很多的归纳学习系统仅专注于单一任务,因此归纳迁移领域的研究者提出了这个问题:如何通过使用多个学习任务的知识来增强学习能力。为达到同等水平的性能,归纳迁移学习可以减少训练样本的数目或训练的迭代次数 ,这对于训练样本不足的学习任务而言是非常有意义的。实验结果表明,在现实中有很多可以应用多任务学习的场景。
首先,多任务学习可以学到多个任务的共享表示,这个共享表示具有较强的抽象能力,能够适应多个不同但相关的目标,通常可以使主任务获得更好的泛化能力。此外,由于使用共享表示,多个任务同时进行预测时,减少了数据来源的数量以及整体模型参数的规模,使预测更加高效。因此,在多个应用领域中,可以利用多任务学习来提高效果或性能,比如垃圾邮件过滤、网页检索、自然语言处理、图像识别、语音识别等。
既然同时学习多个相关任务有重要的意义,那么什么是相关任务?有些理论对任务的相关性的刻画已经很清楚了:
- 如果两个任务是处理输入的相同函数,但是在任务信号中加入独立的噪声处理,很明显这两个任务是相关的。
- 如果两个任务用于预测同个个体的属性的不同方面,这些任务比预测不同个体的属性的不同方面更相关。
- 两个任务共同训练时能相互帮助并不意味着它们是相关的:有时通过在后向传播网络的一个额外输出加入噪声可以提高泛化能力,但是这个噪声任务与其它任务不相关。
随着深度学习被广泛应用,计算机视觉和语音识别领域也有了更深远的发展。深度学习网络是具有多个隐层的神经网络,逐层将输入数据转化成非线性的、更抽象的特征表示。并且深度学习网络中各层的模型参数不是人为设定的,而是给定学习器的参数后在训练过程中学到的,这给了多任务学习施展拳脚的空间,具备足够的能力在训练过程中学习多个任务的共同特征。
直观理解
在迁移学习中,你的步骤是串行的,你从任务A里学习只是然后迁移到任务B。在多任务学习(Muiti-task Learning)中,你是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。
单任务学习:一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
多任务学习:把多个相关(related)的任务放在一起学习,同时学习多个任务。
现在大多数机器学习任务都是单任务学习。对于复杂的问题,也可以分解为简单且相互独立的子问题来单独解决,然后再合并结果,得到最初复杂问题的结果。这样做看似合理,其实是不正确的,因为现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。多任务学习就是为了解决这个问题而诞生的。把多个相关(related)的任务(task)放在一起学习。这样做真的有效吗?答案是肯定的。多个任务之间共享一些因素,它们可以在学习过程中,共享它们所学到的信息,这是单任务学习所具备的。相关联的多任务学习比单任务学习能去的更好的泛化(generalization)效果。
与其他学习算法之间的关系
多任务学习(Multitask learning)是迁移学习算法的一种,迁移学习之前介绍过。定义一个一个源领域source domain和一个目标领域(target domain),在source domain学习,并把学习到的知识迁移到target domain,提升target domain的学习效果(performance)。
多标签学习(Multilabel learning)是多任务学习中的一种,建模多个label之间的相关性,同时对多个label进行建模,多个类别之间共享相同的数据/特征。
多类别学习(Multiclass learning)是多标签学习任务中的一种,对多个相互独立的类别(classes)进行建模。这几个学习之间的关系如图1所示:
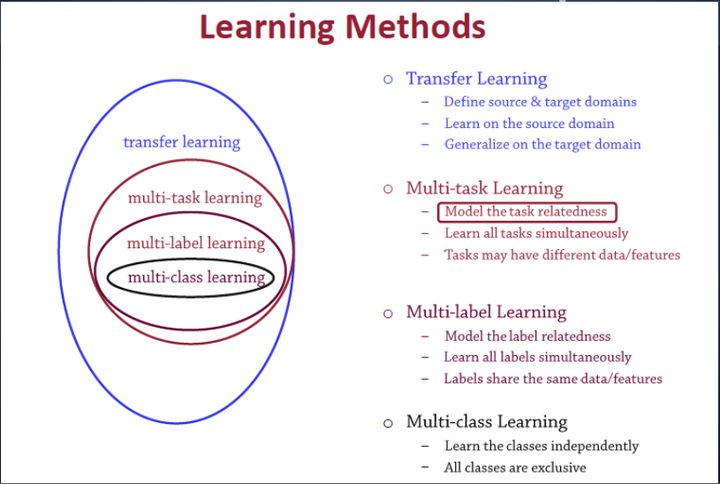
图1 多任务学习与其他机器学习方法之间的关系
多任务学习的定义
多任务学习把多个相关的任务放在一起学习(注意,一定要是相关的任务,后面会给出相关任务(related tasks)的定义,以及他们共享了那些信息),学习过程(training)中通过一个在浅层的共享(shared representation)表示来互相分享、互相补充学习到的领域相关的信息(domain information),互相促进学习,提升泛化的效果。
单任务学习与多任务学习的对比如图2所示。可以发现,单任务学习时,各个任务之间的模型空间(Trained Model)是相互独立的。多任务学习时,多个任务之间的模型空间(Trained Model)是共享的。也就是说,单任务学习时,各个task任务的学习是相互独立的,多任务学习时,多个任务之间的浅层表示共享(shared representation)。
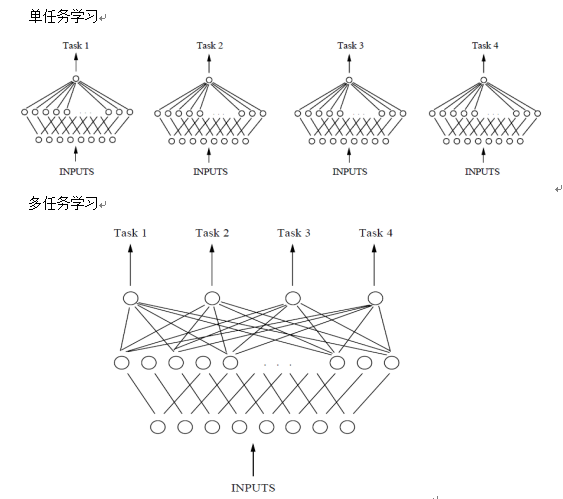
图2 基于单层神经网络的单任务和多任务学习对比
共享表示
共享表示的目的是为了提高泛化(improving generalization),图3中给出了多任务学习最简单的共享方式,多个任务在浅层共享参数。MTL中共享表示有两种方式:
-
基于参数的共享(Parameter based):比如基于神经网络的MTL,高斯处理过程。
-
基于约束的共享(regularization based):比如均值,联合特征(Joint feature)学习(创建一个常见的特征集合)。
效果解释
为什么把多个相关的任务放在一起学习,可以提高学习的效果?关于这个问题,有很多解释。这里列出其中一部分,以图2中由单隐含层神经网络表示的单任务和多任务学习对比为例。
-
多人相关任务放在一起学习,有相关的部分,但也有不相关的部分。当学习一个任务(Main task)时,与该任务不相关的部分,在学习过程中相当于是噪声,因此,引入噪声可以提高学习的泛化(generalization)效果。
-
单任务学习时,梯度的反向传播倾向于陷入局部极小值。多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值。
-
添加的任务可以改变权值更新的动态特性,可能使网络更适合多任务学习。比如,多任务并行学习,提升了浅层共享层(shared representation)的学习速率,可能,较大的学习速率提升了学习效果。
-
多个任务在浅层共享表示,可能削弱了网络的能力,降低网络过拟合,提升了泛化效果。
还有很多潜在的解释,为什么多任务并行学习可以提升学习效果(performance)。多任务学习有效,是因为它是建立在多个相关的,具有共享表示(shared representation)的任务基础之上的,因此,需要定义一下,什么样的任务之间是相关的。
应用场景
-
如果你训练的一组任务,可以共用低层次特征。对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮你识别停车标志,因为这些都是道路上的特征。
- 对于每项任务,数据规模类似。如果你专注于单项任务,如果想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量。
- 训练大型网络。多任务学习会降低性能的唯一情况,和训练单个神经网络相比性能更低的情况就是你的神经网络还不够大。但如果你可以训练一个足够大的神经网络,那么多任务学习肯定不会或者很少会降低性能,我们都希望它可以提升性能,比单独训练神经网络来单独完成各个任务性能要更好。
总结与反思
在实践中,多任务学习的使用频率要低于迁移学习。
我看到很多迁移学习的应用,你需要解决一个问题,但你的训练数据很少,所以你需要找一个数据很多的相关问题来预先学习,并将知识迁移到这个新问题上。
但多任务学习比较少见,就是你需要同时处理很多任务,都要做好,你可以同时训练所有这些任务,也许计算机视觉是一个例子。在物体检测中,我们看到更多使用多任务学习的应用,其中一个神经网络尝试检测一大堆物体,比分别训练不同的神经网络检测物体更好。但我说,平均来说,目前迁移学习使用频率更高,比多任务学习频率要高,但两者都可以成为你的强力工具。
所以总结一下,多任务学习能让你训练一个神经网络来执行许多任务,这可以给你更高的性能,比单独完成各个任务更高的性能。但要注意,实际上迁移学习比多任务学习使用频率更高。