参考博文:周纵苇/xinrui_zhuang/机器之心/jiaotong_jin
背景:目前推广应用的机器学习方法或模型主要解决分类问题,即给定一组数据(文本、图像、视频等),判断数据类别或将同类数据归类等,训练过程依赖于已标注类别的训练数据集。在实验条件下,这些方法或模型可以通过大规模的训练集获得较好的处理效果。然而在应用场景下,能够得到的数据实际上都没有进行人工标注处理,对这些数据进行类别标注所耗费的人力成本和时间成本非常巨大。在一些专门的应用领域,例如医学图像处理,只有专门学科的专业医生能够完成对医学影像图像的数据标注。显然,在这种情况下必须依赖大规模训练集才能使用的方法或模型都不再适用。
1. 简介

为了减少对已标注数据的依赖,研究人员提出了主动学习(Active Learning)方法。主动学习通过某种策略找到未进行类别标注的样本数据中最有价值的数据,交由专家进行人工标注后,将标注数据及其类别标签纳入到训练集中迭代优化分类模型,改进模型的处理效果。
主动学习(Active learning or query learning)作为机器学习的一个分支其主要是针对数据标签较少或打标签“代价”较高这一场景而设计的,在统计学中主动学习又被称为最优实验设计(optimal experimental design)。其主要方式是模型通过与用户或专家进行交互,抛出”query”(unlabeled data)让专家确定数据的标签,如此反复,以期让模型利用较少的标记数据获得较好“性能”。一般情况下,模型抛出的未标注数据为“hard sample”(对于“hard sample”的不同定义可以衍生出一大堆的方法,如可以是ambiguous sample,即模型最难区分的样本;可以是对模型提升(改变)最大的样本,如梯度提升最大;可以是方差减小等等),相比与有监督学习,主动学习通过让模型更多的关注或学习“hard sample”,以期在较少的训练样本下获得较好的模型。
根据最有价值样本数据的获取方式区分,当前主动学习方法主要包括基于池的查询获取方法(query-acquiring/pool-based)和查询合成方法(query-synthesizing)两种。近年来提出的主动学习主要都是查询获取方法,即通过设计查询策略(抽样规则)来选择最具有价值信息的样本数据。与查询获取方法「选择(select)」样本的处理方式不同,查询合成方法「生成(generate)」样本。查询合成方法利用生成模型,例如生成式对抗网络(GAN, Generative Adversarial Networks)等,直接生成样本数据用于模型训练。
问题背景:是不是训练数据集越多,深度学习的效果会越好呢?
需要呈现的结果很简单,横坐标是训练集的样本数,纵坐标是分类的performance,如下图所示:
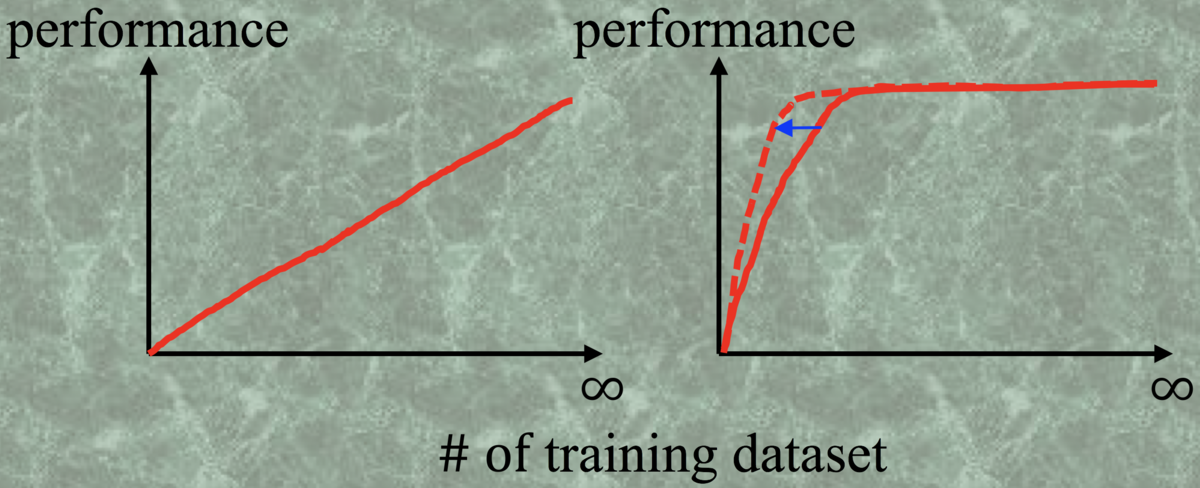
图1-1 训练数据与性能的关系
如果答案是左图,那么就没什么可以说的了,去想办法弄到尽可能多的训练数据集就ok,但是现实结果是右图的红实线,一开始,训练集的样本数增加,分类器的性能快速地在上升,当训练集的样本数达到某一个临界值的时候,就基本不变了。
也就是说,当达到了这个临界的数目时,再去标注数据的ground truth就是在浪费时间和金钱。
这里需要说明的一点是,训练样本数的临界点大小和这个分类问题的难度有关,如果这个分类问题非常简单,如黑白图像分类(白色的是1,黑色的是0),那么这个临界值就特别小,往往几幅图就可以训练一个精度很高的分类器;如果分类问题很复杂,如判断一个肿瘤的良恶性(良性是0,恶性是1),那么这个临界值会很大,因为肿瘤的形状,大小,位置各异,分类器需要学习很多很多的样本,才能达到一个比较稳定的性能。
解决思路:让数据饱和临界值变小,从而降低数据标注代价
本文用主动学习(Active Learning)的手段来挑选标注数据,从而找到一个更小的子集来达到最理想的性能。主动学习(Active Learning),可以主动学习那些比较“难的”,“信息量大的”样本(hard mining)。关键点是每次都挑当前分类器分类效果不理想的那些样本(hard sample)给它训练,假设是训练这部分hard sample对于提升分类器效果最有效而快速。主动学习的核心问题,在于怎样在不知道真正标签的情况下怎么去定义HARD sample?或者说怎么去描述当前分类器对于不同样本的分类结果的好坏?之前的工作基本都是围绕这个问题展开的。
接下来,我们重点关注一下主动学习在医学图像处理中的应用,在第一篇文章中,我将会介绍得详细一些(补充基础知识),之后会将重点放在各方法的优缺点比较上面。
2. 应用(持续更新)
2.2 Biomedical Image Segmentation via Representative Annotation
本文发表在AAAI2019,作者均来自美国圣母大学,Lin Yang, Yizhe Zhang, Jianxu Chen,均为华人,文章标题的中文翻译为:基于代表性注释的生物医学图像分割。在本文中,他们提出了一种新的深度学习框架:代表标注(Representative Annotation, RA),以减少生物医学图像分割中的标注工作。本文使用三个数据集(两个2D和一个3D)评估我们的RA方法,并显示我们的框架与最先进的方法相比产生了有竞争力的分割结果。
拟解决问题:
深度学习已成功地应用于许多生物医学图像分割任务。然而,由于生物医学图像数据的多样性和复杂性,人工注释训练集费时费力,通常只有生物医学专家才能很好地注释图像数据。在主动学习类型的注释方案中,人类专家经常参与一个漫长的迭代注释(Iterative Process)过程。
背景知识:
目前,减轻注释负担的方法主要有两大类。第一类的方法旨在通过利用弱/半监督学习方法来利用无注释的数据。虽然这些方法很有前途,但其性能仍远未达到监督学习方法的水平。在生物医学分析中,准确性是非常重要的,因此性能是一个大问题。
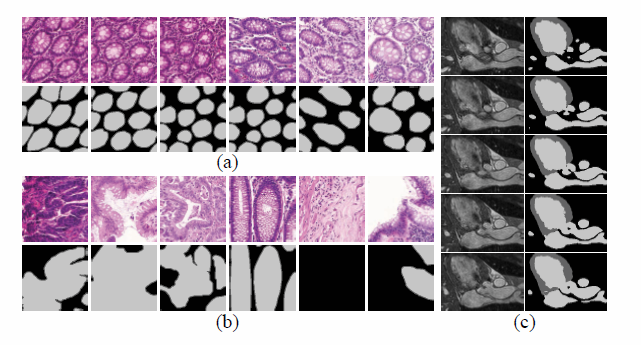
图2-2-1 不同数据集中的数据相似性例子。
第二类方法的目的是识别和注释对最终分割精度有贡献的最有价值的图像区域。为了达到这个目的,这些方法通常探究生物医学图像的以下两个特性。(1)某一类应用的生物医学图像通常是相似的(如腺体分割、心脏分割)。因此,在生物医学图像数据集中可能存在大量的冗余。图2-2-1(a)和(c)分别显示了腺体和心脏CT图像的一些常见模式。(2)虽然生物医学图像中感兴趣区域(ROIs)可能有不同的外观,但我们注意到它们可以大致分为一定数量的组(如图2-2-1(b))。因此,选择具有代表性的样本来覆盖不同的情况,有助于获得良好的分割性能。
使用方法:
主动学习可以从未标记的集合中选择信息样本,并指导人类专家查询标签。本文提出了新的主动学习模型,直接选择具有较高影响和多样性的有效实例进行生物医学图像的一次性分割(即one-shot,没有迭代过程,只训练DL模型一次)。
要实现一次性选择,我们需要应对两大挑战:
-
与AL中模型可以进行人工标注,可以通过监督训练来提取信息特征相比,我们框架中的图像特征提取组件只有原始图像数据,只能进行无监督训练。
-
所有的AL方法主要依赖于未标注图像的不确定性估计(uncertainty estimation),我们的框架中没有用到。相反,我们需要为有价值的ROIs制定一个新的标准。
针对这些问题,本文提出了一种新的数据挖掘框架——代表性标注(representative annotation, RA),使用无监督网络进行特征提取,在学习的特征描述子的潜在空间中选择有代表性的图像块进行标注,在最小化冗余的同时隐式地表征底层数据。具体来说,我们利用基于聚类的方法来减少集群内冗余,并利用最大覆盖(Max-cover)方法来减少集群间冗余,而不牺牲集群间的多样性。以这种方式,选取具有代表性的图像样本。图2-2-2概述了我们的主要思想和步骤。此外,我们的One-shot框架实现了对3D图像的高效注释选择。最后,带注释的选定图像patch训练一个全卷积网络(FCN)进行图像分割。
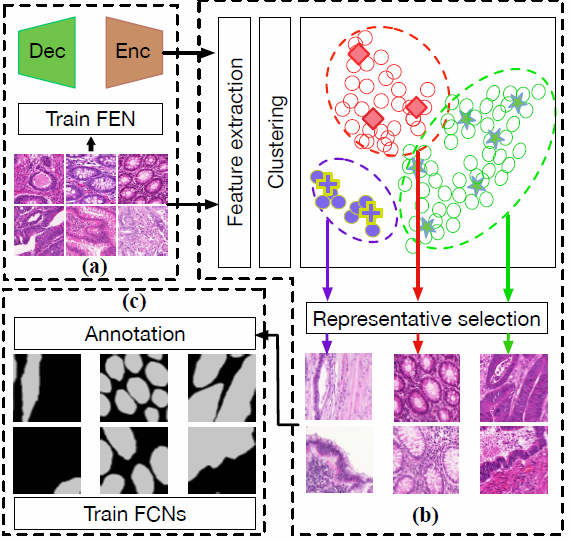
图2-2-2 RA模型的基本流程
实验设置:
我们在两个2d数据集和一个3d数据集上验证RA:2015年MICCAI腺分割挑战(GlaS)数据集,一个fungus数据集,以及2016年HVSMR挑战数据集。对于RS,我们只需要一个无标注训练集来训练我们的特征提取网络(FEN),然后用带注释的图像训练我们的FCN,并在测试集上评估它的分割效果。
GlaS:85张训练图像,包括37良性(Benign),48恶性(Malignant)以及80张测试图像。图像大小均为775*522。本文采取patch+降采样方法处理,总共有1530个patches供RA方法挑选。
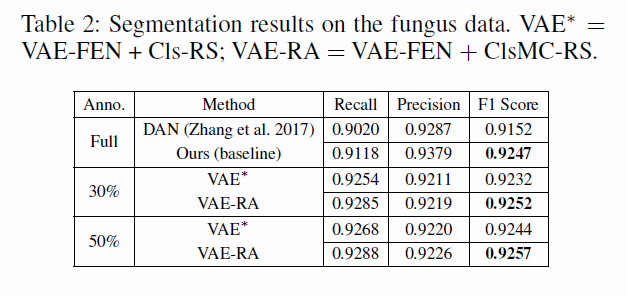
Fungus:84张1658*1658大小的图像,本文采用4张图像作为训练集,80张图像作为测试集。我们从每幅训练图像中截取步长为100像素的patch,形成784个patch的集合进行代表性挑选。
3D HVSMR:HVSMR 2016数据集的目的是在心血管MR图像中分割心肌和大血管(血池)。10个MR图像组成训练集,10个MR图像作为测试集。
首先,本文展示了在完整标注下的先进分割性能,然后在两个方面体现RA的优越性:节省人类注释和对应的分割性能(较其他主动学习方法)。
实验结果:
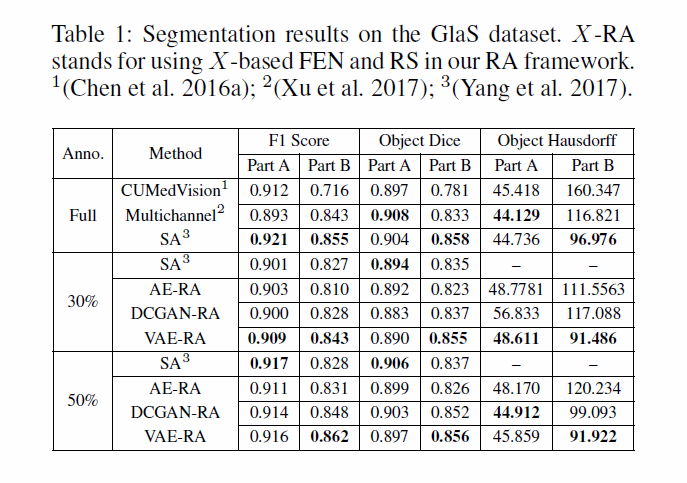
表格1给出了在GlaS数据集上的结果。本文使用与SA(一种sota主动学习方法,后面会更新)使用的FCN相同,在50%数据设定下,结果相近;但在30%数据设定上,RA表现更好。
优点:
我们的RA方案有三个引人注目的优点:
-
它利用了深度神经网络学习图像数据更好表示的能力;
-
需要手动注释的样本一次性(One-shot)选择,使注释者从以往常见的迭代注释过程中解放出来;
-
通过简单的扩展可以部署到3D图像中。
缺点:
- 特征提取仍采用稍显陈旧的自编码器,实际上近年有许多新的特征学习手段(如当下正热门的自监督),甚至比强监督学习的特征提取效果要好;
- 实验采取了三个毫无关系的数据集,实际上无监督可以利用多个相似域的数据,极大程度的扩展数据量;
- One-shot主动学习方法虽然快捷,但是医学图像处理对性能的要求更高,也许迭代式的主动学习方法能更精确、更鲁棒;
- 文章没有开源,复现具体方法困难。