由于成像设备和扫描参数等的不同,医学图像的质量会存在比较大的差异,从而导致模型在某些数据集上性能下降。有什么方法解决这个问题?
另外,对于医学图像处理,到底是否应该从ImageNet进行迁移学习?
迁移学习是否能够有效减少标注数据的使用?
今天,让我们重新思考医学图像处理中的迁移学习。
Transfusion: Understanding Transfer Learning for Medical Imaging
这篇论文是由Google与Bengio等人合著,并发表在了NIPS2019上面,题目译文:迁移融合:理解医学成像中的迁移学习。
本文的主要目的是探讨迁移学习在医学图像处理中的作用,即讨论迁移学习对于医学任务来说是不是必要的。当然,医学成像有多种数据库,本文主要使用彩色眼底图像(DR检测)和X-ray胸片(CheXpert)上进行实验。
论文的主要发现有以下几点:
- 迁移学习不会显著影响医疗成像任务的性能,从零开始训练(train from scratch)的模型的性能几乎与标准 ImageNet迁移模型接近;
- 转移学习提供的性能增益有限,甚至使用更小的架构CBR也可以和标准的
ImageNet模型性能相当(以往学界认为大型网络可以显著提升性能),为 ImageNet 设计的大型模型对于非常小的数据集可能过于高估; - 由于 CBR 模型比标准 ImageNet 模型小得多、更浅,因此在 ImageNet 分类中性能差得多,这突出表明 ImageNet 性能并不代表医疗任务的性能。标准ImageNet的性能差异和模型的过度参数化(
over-parametrization)有关,并非源于精细的特征重用; - 有意义的特性重用只集中在最低层(前两层),而且大型预训练模型在细调(
fine-tune)的时候,模型参数变化缓慢(即使在random initialization设置中),重用最低层会使收敛速度得到最大的提高,如图1所示。
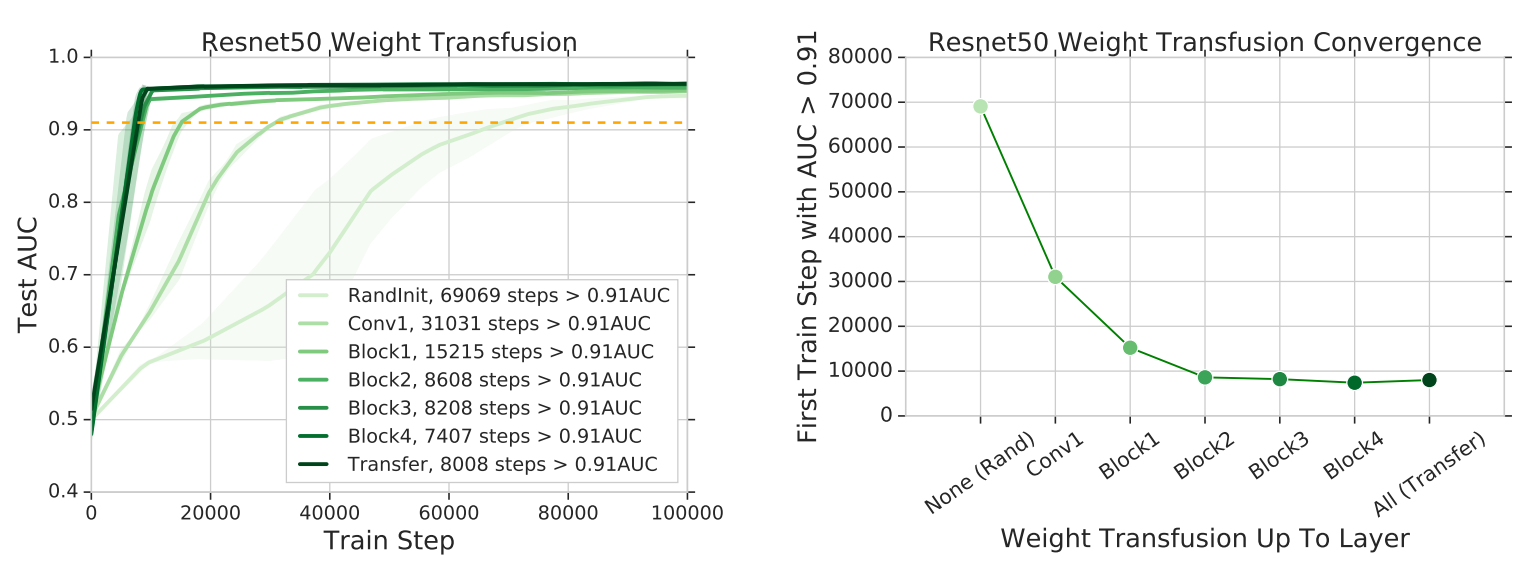
图1 重用权重子集与收敛速度的关系。
在对论文通读后,我认为对于医学图像处理,本论文的主要贡献如下:
- 印证了在MIA中,我们同样高估了迁移学习的能力,真正有用的信息只集中在前两层;
- 说明了迁移学习预训练中学习到的特征并没有想象中的强泛化(generalization)能力(Quoc V Le et al.)。
启发和思考:
对于医学图像处理这种细粒度分类问题,ImageNet迁移学习不一定能够帮助我们学习良好的特征提取;即使是非常相似的领域,迁移学习也不一定能提升性能(Kaiming He et al.),在医学成像中,由于成像设备和扫描参数等的差异,医学图像的质量会存在较大差异,从而导致模型在临床应用中的性能下降。如何有效解决域迁移性能下降的问题,是困扰学术界的核心问题之一。
另外,对于我关注的自监督领域,虽然同样也是得到预训练模型,但是与迁移学习不同的是,自监督预训练模型使用目标域的无标注数据训练,因此可以更好的提取当前任务的特征,不用考虑特征重用的问题,从根本上杜绝了
domain gap的问题。也许在临床应用中,利用好大量无标注的数据比构建所谓的Medical ImageNet更重要。
补充:
个人以为医学分类任务非常接近细粒度(Fine-grained)分类问题:即识别细分类别的任务,一般它需要同时使用全局图像信息与局部图像信息精准识别图像子类别。
医学成像任务往往从感兴趣的身体区域的大图像开始,并使用局部纹理的变化来识别病理。如图2所示,在视网膜眼底图像中,红色小点是微动脉瘤和糖尿病视网膜病变的标志,在胸部x光片中,局部白色不透明斑块是结节和肺炎的标志。这与像ImageNet这样的自然图像数据集形成了对比,在自然图像数据集中,图像通常有一个清晰的全局主题。

图2:分别来自ImageNet、视网膜眼底照片和CheXpert数据集的示例图像。眼底照片和胸部x光片比ImageNet图像分辨率高得多,通过寻找组织的局部小变化来分类。